SISD (Single Instruction, Single Data)
Este es el modelo tradicional de computación
secuencial donde una unidad de procesamiento recibe una sola secuencia de
instrucciones que operan en una secuencia de datos.
Se refiere
a las computadoras convencionales de Von Neuman. Ejemplo: PC’s.
En la
categoría SISD están la gran mayoría de las computadoras existentes. Son
equipos con un solo procesador que trabaja sobre un solo dato a la vez. A estos
equipos se les llama también computadoras secuenciales.
SIMD (Single Instruction, Single Data)
A diferencia de SISD, en este caso se tienen múltiples
procesadores que sincronizadamente ejecutan la misma secuencia de
instrucciones, pero en diferentes datos.
El tipo de memoria que estos sistemas utilizan es
distribuida.
Arreglo de
procesadores. Cada procesador sigue el mismo conjunto de instrucciones;
diferentes elementos de información son asignados a cada procesador.
Típicamente tienen miles procesadores simples. Son utilizadas en redes
neuronales.
Las
computadoras SIMD tienen una sola unidad de control y múltiples unidades
funcionales. La unidad de control se encarga de enviar la misma instrucción a
todas las unidades funcionales. Cada unidad funcional trabaja sobre datos
diferentes. Estos equipos son de propósito específico, es decir, son apropiados
para ciertas aplicaciones particulares, como por ejemplo el procesamiento de
imágenes.
Un ejemplo
sería un conjunto de equipos que trata de factorizar un número primo muy grande
utilizando diferentes algoritmos.
MIMD (Multiple Instruction,
Multiple Data)
Múltiples computadoras y multiprocesadores. Las piezas de código
distribuidas entre los procesadores. Los procesadores pueden ejecutar la misma
o instrucción o diferentes instrucciones. Se puede decir que MIMD es un super
conjunto de SIMD.
Diferentes elementos de información se asignan a diferentes
procesadores. Pueden tener memoria distribuida o compartida.
Cada procesador MIMD corre casi independientemente de los otros.
Las computadoras MIMD pueden ser utilizadas en aplicaciones con
información en paralelo o con tareas en paralelo.
En la categoría MIMD están los equipos con varios procesadores
completos. Cada procesador tiene su propia unidad de control y su propia unidad
funcional. Esta categoría incluye varios subgrupos: Equipos de memoria
compartida, equipos de memoria distribuida y redes de computadores. Los equipos
MIMD son de propósito general.
MISD (Multiple Instruction, Single Data)
Varias unidades funcionales ejecutan diferentes operaciones sobre el
mismo conjunto de datos.
• Las arquitecturas de tipo pipeline pertenecen a esta clasificación
• aunque no puramente, ya que pueden modificar los datos sobre los que
operan.
• Systolic arrays, FPGA celulares.
• También pertenecen los computadores tolerantes a fallos que utilizan
ejecución redundante para detectar y enmascarar errores.
• No existen otras implementaciones específicas.
• Los modelos MIMD y SIMD son más apropiados para la aplicación del paralelismo
tanto a nivel de datos como de control.
Procesadores Vectoriales
Orientados a ejecutar eficientemente
algoritmos numéricos sobre estructuras regulares de un gran número de elementos
Incluyen en su repertorio de instrucciones,
instrucciones capaces de procesar vectores, aparece un nuevo tipo de dato “vector”.
Cada vez que una instrucción es ejecutada,
se ejecuta idealmente sobre todos los componentes del vector Las operaciones
sobre vectores pueden realizarse más rápido que una secuencia de operaciones
escalares sobre el mismo número de elementos.
Es necesario realizar una selección de
aplicaciones, datos y compiladores
Arreglo Sistolico
Un arreglo sistólico es un conjunto de procesadores dispuestos de una
manera regular (por lo general rectangular) donde los datos fluyen
sincrónicamente a través del arreglo entre sus vecinos.
Cada procesador toma en cada paso toma datos de sus vecinos (por lo
general Norte y Oeste), los procesa y se los entrega a sus procesadores vecinos
(por lo general Sur y Este).
Arquitectura Multiprocesador memoria compartida
UMA = Uniform Memory Access
– Acceso uniforme (todos los procesadores acceden a la memoria en el
mismo tiempo).
– Multiprocesadores simétricos (SMP).
– Pocos procesadores (32, 64, 128, por problemas de ancho de banda del
canal de acceso).
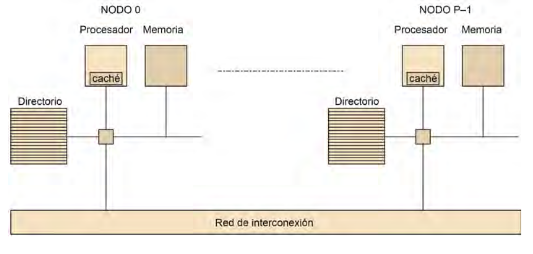
NUMA = Non-Uniform Memory Access.
– Colección de memorias separadas que forman un espacio de memoria
direccionable.
– Algunos accesos a memoria son más rápidos que otros, como consecuencia
de la disposición física de las memorias
(distribuidas físicamente).
– Multiprocesadores masivamente paralelos (MPP).
Multicomputadores
La principal característica de los multicomputadores es que los procesadores, al más bajo nivel, ya no pueden compartir datos a través de loads/stores, sino que lo tienen que hacer por medio de mensajes. Es por eso por lo que en este tipo de sistemas no hay problemas de coherencia de caché ni de consistencia de memoria. Aquí, la sincronización se hace explícita con los mensajes, tal y como muestra la figura 40, con primitivas estilo send y receive. En el send se especifíca el buffer a enviar y a quién se envía. Por el otro lado, el receive debe especificar el buffer de recepción y de quién lo recibe. Los buffer del send y del receive están en espacios de direcciones diferentes, suponiendo que son procesos diferentes. Opcionalmente, también se puede especificar una etiqueta o tag al mensaje, para recibir un mensaje concreto de un procesador concreto, cumpliéndose la matching rule.












{kind=link}